Self-Supervised Vision Transformers
Self-Supervised Vision Transformers (DINO):
One paper I’ve been wanting to understand, at least at a high level, is DINO. DINO is another “learn a good representation of images” through self-supervision paper. In order to understand DINO I had to first take a detour into some contrastive learning literature which I wrote about here.
Let’s jump right in! Below is a figure showing the broad architecture of DINO.
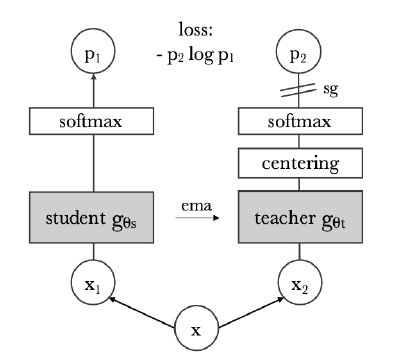
If you are familiar with BYOL you will notice that this architecture is very similar. What are the similarities?
- Once again we have a source image \(x\) that is used to generate two different views/augmentations \(x_{1}\) and \(x_{2}\) (in this work there is a set of views).
- The views are fed into a student and teacher respectively which have the same architecture but different parameters.
- The teacher parameters are based on an exponential moving average of the student parameters.
- Only the student learns.
Some areas where DINO is different than BYOL:
- DINO uses a vision transformer for the encoder.
- The DINO the architecture is simpler in that the student (corresponding to the oneline network) and teacher (target network) don’t connect to additional neural networks.
- The teacher encoder outputs are fed through a centering operation which shifts the logits (there is also sharpening during the softmax).
- The student and teacher both generate probability distributions over \(K\) “classes” which feed into a cross entropy loss that is used for training.
- In DINO, a set of views are generated during augmentation and they can be more global (big crop) or local (small crop).
- Multiple views are fed through the student and teacher with the caveat that the teacher only gets the global views.
Related to the last bullet, an interesting aspect to the loss function used in this work is that it is a sum of cross entropy losses. That means the teacher is outputting probability distributions for all of the global views/augmentations and those are compared with probability distributions output by the student for all of the views. In general this is encouraging the student to match the teacher even if the student only sees a small part of the image. My interpretation is that the model is forced to learn the essence of the image by predicting that essence from smaller pieces. Kind of like predicting the theme of a jig-saw puzzle from smaller pieces.
Another interesting result from this paper is the visualization of attention maps from multiple heads. The way these maps are produced is by taking the encoder output corresponding to the [CLS] token and comparing it with the encoder outputs corresponding to different image patches. In the figure below we see these attention maps with different colors representing different attention heads. What’s impressive is how much the attention map looks like a segmentation map. In the first (top-left) image we see the model attends most strongly to the food on the plate and that different attention heads focus on different foods.

Conclusion
DINO demonstrates that you can learn a powerful representation of images by marrying the vision transformer with a contrastive-learning-like model without the need for labels. DINO also shows us through attention maps that transformers learn representations which reflect the key/salient objects in the image.
That said, I still find it surprising that these self-supervised models rooted in contrastive learning actually work. It kind of feels like all we are telling the model is that two different but related images should be encoded in a similar way and that somehow this is enough for the model to learn. The answer may just be with enough scale simple-ish models can do amazing things.
References
- DINO
- DINO YT Video Once again thanks to Yannic Kilcher for his great videos!